
¶ Why you should use PADME!
Data - A very generic but also complex term. It is linked to a lot of exciting activities like artificial intelligence but it is also linked to high responsibility if we regard data privacy. In order to use it, we must analyze it. However, data is not always stored in a central place - different data islands exist. These data islands are not not necessarily findable nor accessible.
Additionally, isolated data might be stored in a non-standardized format which makes it hard to reuse it for analytical tasks.
¶ Centralised Analytics - Bring data to analysis
Using the centralised approach for analytics the data is brought to a central place. This, however, poses a risk for the data sovereignty, privacy and the performance, because the data has to leave the institutions.

| Centralised Analytics | Disadvantages |
|---|---|
|
|
The solution to these problems is to reverse the process - instead of transferring the data to the analysis the analysis is now brought to the data. These so-called Distributed Analytics are presented in the following.
¶ Distributed Analytics - Bring analysis to data
Instead of transferring the data to the analysis as in Centralised Analytics, this process is reversed by transferring the analysis to the data. Consequently, the data does not leave the institutions for analysis and the data sovereignty is kept. Additionally, in the age of Big Data, the analysis task’s size is way smaller than the combined data sizes of all institutions, so the network load due to the data amount is reduced. Most importantly, this process is also generally GDPR compliant, because the medical data is not transferred to a potentially insecure entity.
In order to analyse the data distributively, two different approaches can be chosen: Institutional Incremental Learning (IIL) and Federated Learning. The two approaches differ in how the analysed data from an institution is aggregated with the other institutions’ analysis results. With IIL the institutions’ analysis results are forwarded to the next institution where the analysis is then performed. This requires communication and therefore knowledge from the institutions among themselves. Federated Learning uses a Result Aggregator for communication and analysis result exchange between the institutions. Consequently, the institutions must not have knowledge from each other. The Result Aggregator only sends the previous analysis results together with the analysis task to the institution.

| Distributed Analytics | Advantages |
|---|---|
|
|
The Personal Health Train is the infrastructure supporting Distributed Analytics among other things. It will presented in the following section.
¶ The Personal Health Train (PHT)
The Personal Health Train is a distributed infrastructure based on the FAIR principles from the GoFAIR initiative GoFAIR initiative which supports
- Data management
- Data analysis
- Medical decision making

It is based on the following guiding principles:
- Control over data
- Reusable health data
- Distributed and federated solutions
- International interoperability
- Responsible use of health data
- Ethics-by-design
- Machine-readability at the core
The concept of the PHT which enables it to perform Distributed Analytics is shown in the following.
¶ Concept
The concept of the Personal Health Train can be imagined as a train addressing different stations. The payload of the train includes the analysis task together with the previous stations’ results. The train track is a predefined route the train has, thus in which order the analysis is performed at each station.
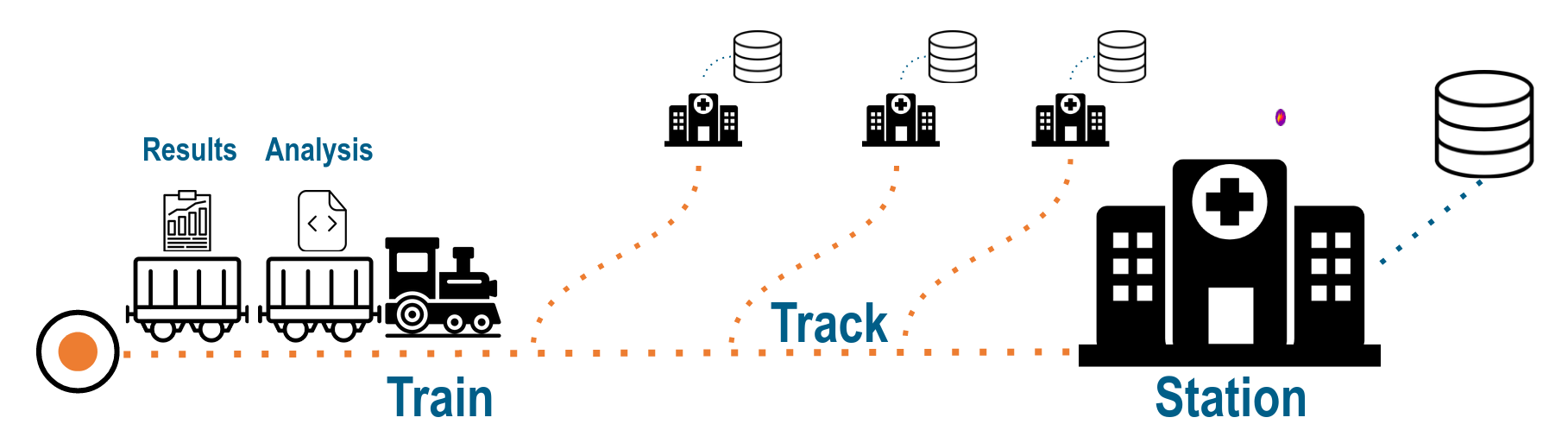
¶ Trains
- Trains are self-sufficient
- Operating system, software, and library dependencies
- Algorithm and query (static)
- Results, e.g., ML model (dynamic)
¶ Stations
- Curate confidential data
- Expose data in a discoverable format
- Provide computational resources
- Execute analytic tasks (Trains) in a secure environment
In the following, we will get a technical overview.
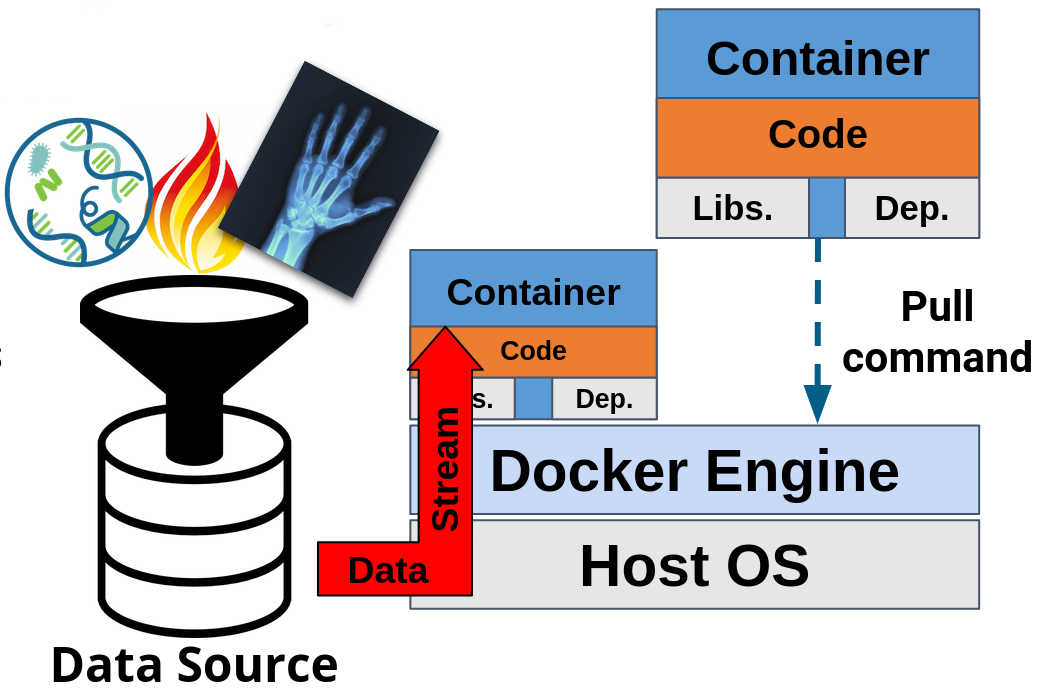
¶ Technical Overview
The PHT is based on containerization technology, namely Docker. Docker uses OS-level virtualization. It ensures that the applications running within a container, have their own operating system environment with their own user space, but because of the shared kernel the performance overhead is reduced in comparison to virtual machines. Additionally, it forces inter-container communication through well-defined channels, which limits possible attack surfaces. The following is a sampling of the key benefits of Docker:
- OS-independent
- Flexible choice of data sources
- Scalability
- Programming language agnostic
¶ PADME
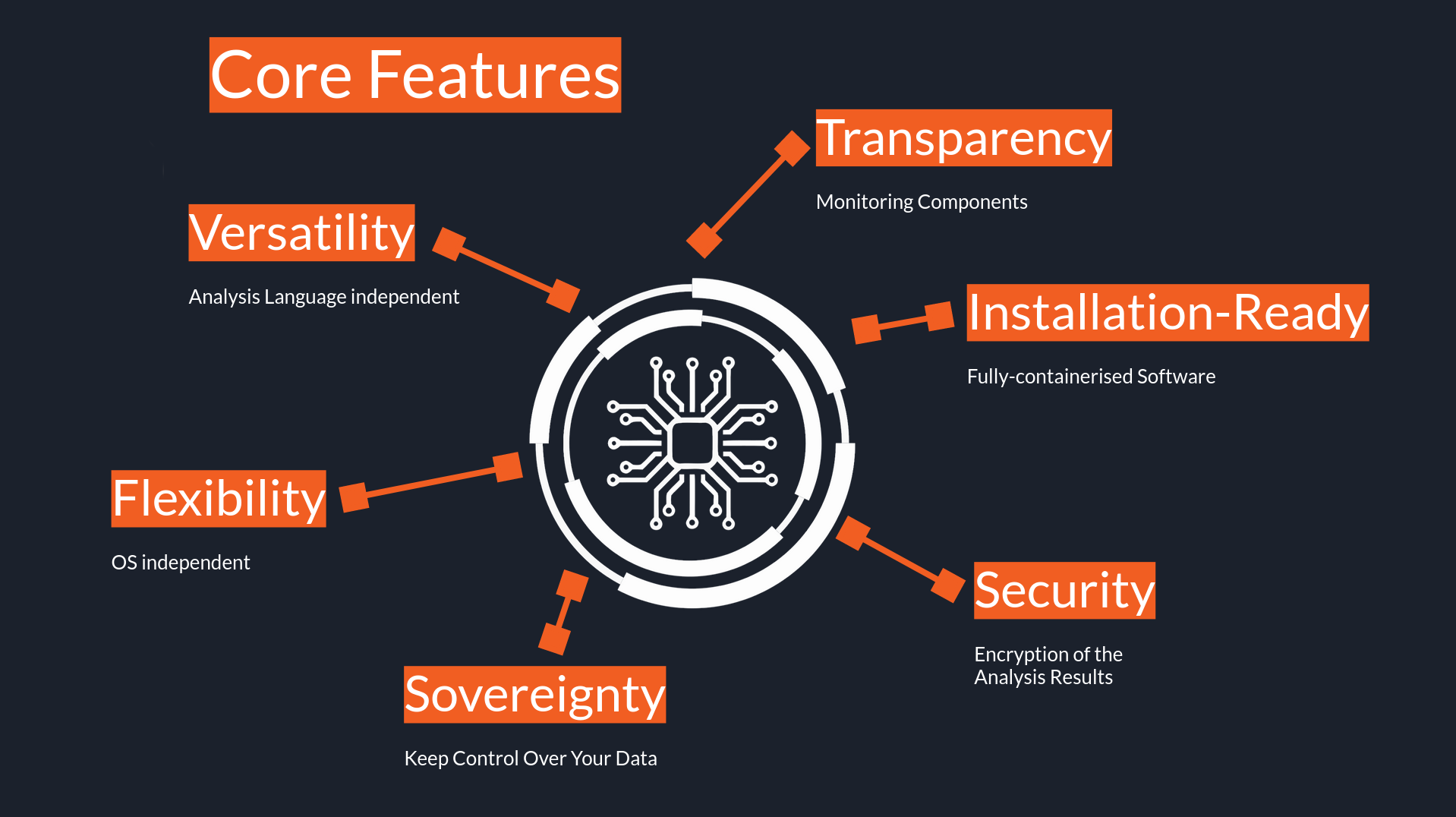
PADME is our Distributed Analytics Infrastructure based on the Personal Health Train (PHT). Its core architecture consists mainly of four different components:
- Station Registry
- Train Builder & Storehouse
- Train Requester
- Station Software
It enables different data sources to provide their data distributively for analysis in a secure, privacy-preserving. and efficient manner. Its usage has been already proven in several projects.
If you have any additional questions do not hesitate to contact us!
For the BETTER Project, use this contact point.