¶ Overview of the PADME Ecosytem
On this page, we provide a top-level view about PADME and its context.
Further information can be found in the work by Welten et al..
¶ Introduction
In health care environments, such as hospitals or medical centres, a large amount of data is collected describing symptoms, diagnoses, and various aspects of the patient’s
cure process. The recorded data is usually reused for reviewing and comparing patient’s state at the time when the patient visits the medical center again. In few cases,
selected data—sometimes data of specific investigations—is shared for continued patient care process, for example, when the patient moves to another hospital. Apart from this data sharing, health care data is one fundamental source for medical research. This includes building cohorts for upcoming or running clinical studies as well as investigating in testing medical hypotheses and determining patients in emergent situations, such as virus outbreaks.
The study results often depend on the number of available patient data. Typically, the more the data is available for the
intended analysis or the scientific hypotheses, the more stable the results are. However, the reuse of patient data for medical research is often limited to data sets available at a single medical centre. The most immanent reasons why medical data is not heavily shared for research across
institutional borders rely on ethical, legal, and privacy aspects and rules. Such rules are typically guarded by national and international laws, such as General Data Protection Regulation (GDPR) in Europe, Health Insurance Portability and Accountability Act (HIPAA) in the U.S., or the Data Protection Act (DPA) in the U.K. limiting sharing sensitive data. These limitations tremendously affect medical research directions, in which a data set is not sufficiently available at each single hospital. Due to these limitations, solutions for distributed analytics (DA) have fuelled the progress of privacy-preserving data analysis by bringing the algorithm to the data. Consequently, by design,
sensitive data never leaves its origin and the data owner keeps the sovereignty over the data. Therefore, this paradigm shift poses a first step towards compliance with the above-mentioned regulations.
We present our DA infrastructure, which has been built upon the established so-called Personal Health Train (PHT) paradigm. We further present novel, data provider-centric, and privacy-enhancing features enabling transparency of the activities within the DA ecosystems and privacy preservation of possibly sensitive analysis results. Lastly, we briefly compare our infrastructure with other DA implementations.
¶ Background
In recent years, several emerging technologies and approaches have been proposed to enable privacy-preserving (scientific) usage of sensitive data in the scope of DA and decentralised data1,2,3,4,5,6.
In general, two prominent DA paradigms can be derived. One paradigm is the parallel approach. Architectures following this pattern send multiple replicas of the analysis including queries, algorithms or statistical models to the data providers and have a protocol to train a data model - so-called Federated Learning (FL) - or an aggregation component, which merges the (query) results of each client3,5.
In contrast to this parallel approach, there exists a non-parallel paradigm1,4.
Instead of a central aggregation server, the intermediate results are transmitted directly or via a handler unit from data provider to data provider.
The results are incrementally updated and returned to the requester after a pre-defined number of data provider visitations. Some recent works defined this as Institutional Incremental Learning (IIL) or Weight Transfer (WT)1,7.
Several infrastructures and platforms are based on these (abstract) principles. One concept following the latter paradigm is the above-mentioned PHT, which has been applied to several use cases by the scientific community8,9,10,11,12. From a top-level perspective, the PHT uses containerisation technologies in order to encapsulate the statistical algorithm, which is transmitted from institution to institution. These containers are executed on-site without the need to pre-install any dependency, which enables flexibility with respect to the used programming language and the data storage technology8. Another DA-enabling technology is DataShield13. DataShield is a distributed infrastructure, which primarily follows the federated (client-server) analytics approach, intended to conduct non-disclosive analysis of biomedical, healthcare and social science data13,14,15.
Instead of containerising the algorithmic code, DataShield relies on REST-interfaces establishing the connection between the DataShield client and a DataShield server (OPAL Server) installed at each institute, which receives the analysis command and executes it. For the execution of the analysis, DataShield uses the programming language R as the framework for the statistical analysis.
An additional concept, which can be interpreted as part of DA, is Secure Multiparty Computation (SMPC). SMPC involves a cryptographic protocol to calculate a result set, where the data of each participating party remains concealed. A simple protocol might be noise induction, i.e., additive secret sharing, to the result set which makes a (malicious) derivation of the actual result set ambiguous16,17,18. However, more complex protocols applying homomorphic encryption techniques are also feasible19. While multiple SMPC frameworks have been developed in the past, most approaches are impeded by the connection and network setup of the participating entities due to the computational overhead induced by the chosen SMPC protocol. Especially, if the level of computational complexity increases (e.g. additional parties or more complex tasks), the network bandwidth could pose a significant bottleneck yielding inefficient runtimes. Despite these community- and research-driven solutions, commercial DA solutions have attracted attention during the past years. FL for healthcare practitioners has been powered by the NVIDIA Clara FL SDK. For example, the initiative EXAM, involving twenty individual hospitals, used the Clara framework to train a model, which predicts Oxygen needs for COVID-19 patients. Further, Tensorflow Federated (TFF) has been proposed by Google, which has been developed to facilitate collaboratively train a shared model on separated locations.
However, these commercial products restrict the users to the provided software and hardware, e.g., both Clara FL and TFF are based on tensorflow/python and Clara FL is built upon the so-called NVIDIA EGX edge computing platform. These circumstances pose challenges with respect to the applicability of such platforms since, on the one hand, the data providers have very strict and varying regulations with respect to third party software executed on their site, which complicates the data provision even more. On the other side, these commercial solutions are limited by the provided frameworks or SDKs. This makes these solutions inflexible with respect to other popular programming languages like R (programming language dependency).
Nevertheless, while R is a well-established tool for statistical analysis, it also lacks functionality with respect to the training of complex Deep Learning (DL) models with DataShield since the R toolbox is limited to selected functions and methods13,15. Moreover, the DataShield packages are deployed to an OPAL server, which restricts the analysis to a predefined data source executing the R commands).
¶ Architectural Overview
The PHT originates from an analogy from the real world. The infrastructure reminds of a railway system including trains, stations, and train depots. The train uses the network to visit different stations to transport, e.g., several goods.
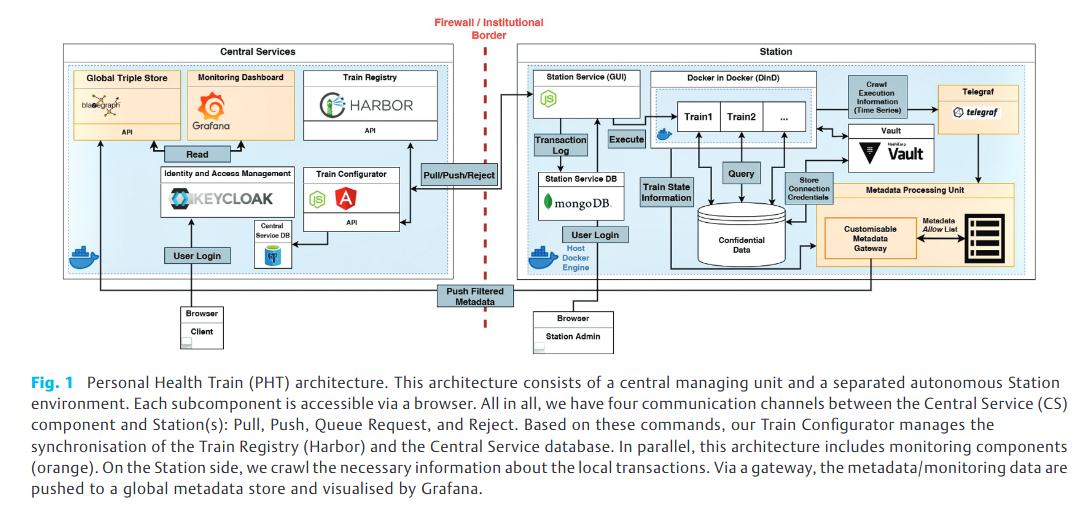
Adapting this concept to the PHT ecosystem, we can draw the following similarities. The Train (Section 3.2) encapsulates an analytical task, which is represented by the good in the analogy. The data provider takes over the role of a reachable Station (Section 3.3), which can be accessed by the Train. Further, the Station executes the task, which processes the available data. The depot is represented by our Central Service (CS, Section 3.4) including procedures for Train orchestration, operational logic, business logic, and data management.
Furthermore, we pay attention to the following design aspects. Every component of our architecture is containerised using the Docker technology to facilitate software development. In addition, the components are loosely coupled to enable possible extensions and (REST API) web service orchestration. For improved usability, each node is accessible via a browser. Moreover, we aim to achieve transparent activities by applying novel monitoring components for the Train requester (Section 3.5). Finally, implemented security-related features (Section 3.6) alleviate the danger of possible data leaks.
Figure 1 gives a high-level overview of the architecture components, which will be discussed in the next sections.
¶ Trains
In general, Trains contain specific analysis tasks, which are executed at distributed data nodes - the Stations (Section 3.3). In order to complete their task, a Train moves from Station to Station to consume data as an outcome of the executed analytical task. The Train requester, e.g., a researcher, selects the Station sequence to be visited. The results are incrementally generated and can be anything based on the Train code. For example, the result set can contain data on an aggregated level, e.g., number showing a cohort size, which has no relationship to individual patient data of the input level, or updated parameters of a statistical model, such as a regression model that is incrementally fitted from Station to Station.
In our architecture, the analysis code is encapsulated in an Open-Container-Initiative-compliant (OCI image - specifically, in a Docker image with pre-defined input interfaces for the data stream and output interfaces for the results, which are stored inside the container itself. This design choice provides extendibility of our architecture such that data nodes can be added easily without restricting them to certain operation system requirements to run the Train. This enables a self-sufficient execution of the analytical task, which implies that no additional installation is needed. Every necessary dependency to run the code is captured within the image. Thus, algorithm designers do not have to deal with the variety of environments in the data nodes. Consequentially, the analytic tasks can be written in any programming language. Further, the Train is enriched with metadata to increase the transparency of the analytical tasks consuming sensitive data. This metadata provides, e.g., information about the data the code is accessing or information about the Train creator20.
The Train itself is executed in a so-called Docker-in-Docker (DinD) container. With this approach, we isolate the Train execution from the host Docker engine and create sandbox-inspired runtime environment, which involves another layer of security.
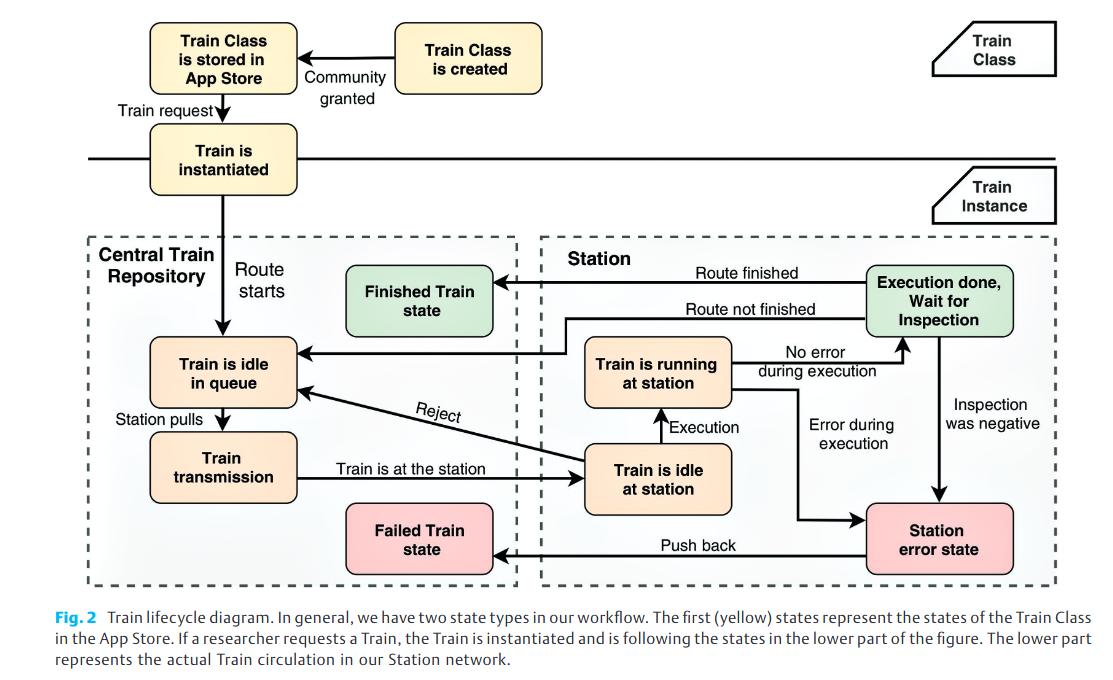
Trains can have several states in their lifecycle, which adds transparency about the state-flow of a Train itself and provides information about the Train status to the users. Possible states are illustrated in Figure 2.
First, a Train Class is created and stored in a so-called App Store (Train Class Repository) after the domain community examined the Train to prohibit malicious code executions at the Stations. If a researcher wants to conduct a data study, the researcher selects a suitable Train Class and a new Train Instance is created. According to our workflow definition, a Train can be in an idle state if it waits in the queue for being pulled by a Station. After the transmission, the Train remains in the idle state until it is transferred to the running state if the Station executes it. If the Train execution at a Station was successful, the Train is pushed back to the repository and the workflow starts again at the next Station defined in the route. In unsuccessful cases, the Train is also pushed back but for debugging purposes and the sequence stops.
Further, the statechart (Figure 2) includes corresponding states if the Station sequence was processed successfully or an error occurred. Finally, the Train requester is able to inspect the results. The advantage is that at any point in time, the Train requester is aware of the current state, which is leverage for the usability of such a network.
¶ Stations
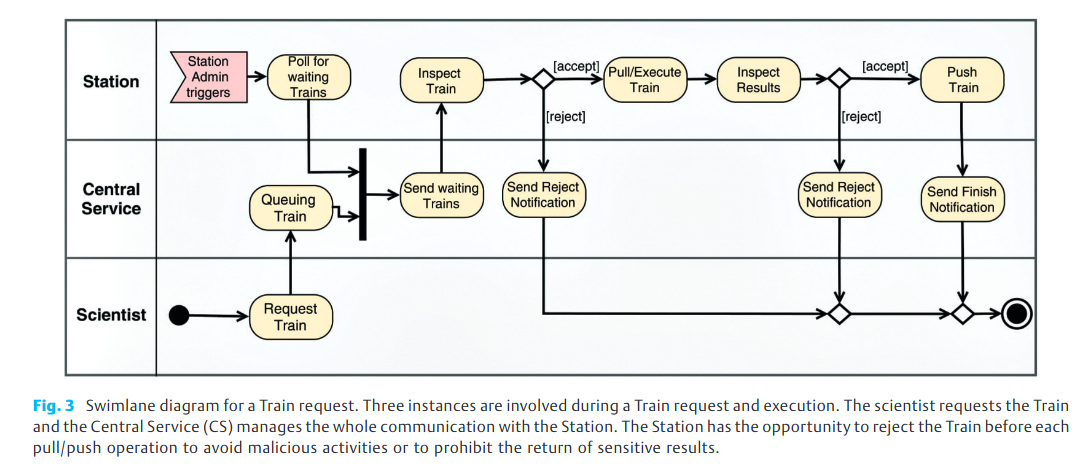
Stations are the nodes in the distributed architecture that hold confidential data and execute analytic tasks (see Figure 1). Each Station is registered in a Station Registry and acts as an autonomous and independent unit. In the distributed architecture, the communication is designed to be one-way, i.e., Stations are actively polling the CS if there are Train requests waiting to be executed. In contrast, the CS does not have an active channel to the Station such that the Station admins or curators of privacy-sensitive data have at any time the high-level sovereignty of any pull, execution, or push activities affecting the corresponding Station. They decide independently to accept or reject requested analytical tasks. Figure 3 presents this policy. After the Train is queued and the Station obtained the list of all waiting Trains, the Station admin is able to reject a Train, e.g., due to doubts about the data usage or a lack of capacity. Further, after passing the first quality assurance, the Train is executed. As the last step, the Station admin inspects the Train results. The Train can be rejected if the result set contains confidential information. Hence, it is ensured that only privacy-conform results leave the Station boundaries.
The Station has two main components: The data source and the Station software (see Figure 1). The Station can hold the data itself or provides an access point to the sensitive data. The main task of the Stations is the execution of the containerised analytic algorithms. Therefore, every Station communicates with a local Docker engine to execute a Train. This execution consists of five steps, i.e., pulling image from Train Registry to the local machine, creating and starting the container of the corresponding pulled Train image, committing the container to create a new image from the container’s changes, and pushing the changed image back to the Train Repository. Furthermore, since the data providers or institutions could have different authentication procedures, we do not restrict the Station software to one single authentication technology and leave the integration of the authentication mechanism to the institution.
In addition, each Station provides a graphical user interface representing a management console to coordinate the Train execution cycle (see the lower part of Figure 2).
¶ Central Services
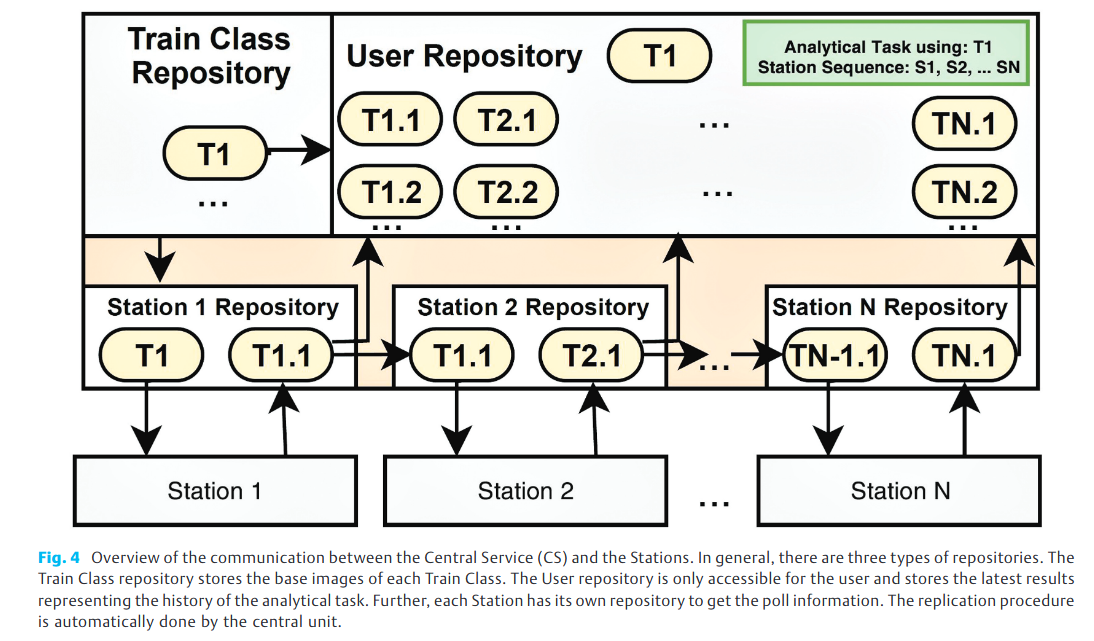
The CS (see Figure 1) provides several monitoring and management services, e.g., to define and execute the Station sequence, to secure intermediate and final results generated by the Trains, and to provide interfaces to the repositories of each operating partner in our architecture. In Figure 4, we depicted a general workflow of our CS. First, it covers a so-called Train Class Repository. Researchers and scientists are able to propose and store their developed analytic algorithms containerised in a base image, which is termed Train Class, and make them available to others. If the researcher requests an analytical job and defines a sequence of Stations to be visited, the CS replicates the base image and stores it in the repository of the first positioned Station in the sequence. After the Station pulled, executed, and pushed the Train back, the CS copies the new Train image into two repositories: The User Repository representing the execution history and the repository of the next Station in the sequence for the subsequent Train execution.
The CS is developed as a REST web service running on an Apache Web Server. This service utilises APIs and Webhooks to trigger the above-mentioned procedures, e.g., Train pulled, Train pushed or Train rejected. As central Train Repository, we use Harbor to store the Train images and to provide role-based and access-controlled (RBAC) repositories.
Further, researchers are able to create analytic jobs and define the Station sequence through a GUI, which is connected to a Station Registry. This registry captures every participating Station and manages required metadata about the Stations. The GUI queries (API) only those Stations for the sequence definition, for which the researcher is authorised. This involves an additional layer of security in our architecture. The access for scientists and researchers is controlled by an identity and access management (IAM) component on the central unit. As IAM, we use the open-source software Keycloak to manage user accounts and access authorisations for components of our central services.
¶ Monitoring Components
In addition to the basic operative functionality of our infrastructure (e.g. Train management), we experienced rising non-transparency if the number of participating parties, especially Stations, increases. This blackbox-alike behaviour of these architectures does not contribute to trust between the involved actors. For example, a Train requester might not necessarily be informed about the current Train position or state. On the other hand, the Station admin should have detailed information about each Train which arrives at the Station. In order to tackle this problem of lacking information, we developed a novel metadata schema, which enriches each incorporated digital asset with detailed semantics, in one of our previous works20. This metadata schema - based on RDF(S) - is used by our monitoring components to provide descriptive information to the actors (see orange components in Figure 1). Each Station has a so-called Metadata Processing Unit, which saves static metadata about the Station (e.g. Station owner, available datasets) or collects dynamic Train execution information (e.g. current state or CPU consumption) from the DinD engine. The dynamic data instances are gathered, converted according to the schema standard and sent to the global metadata store, which is located in the CS. The triple store acts as a backend for the Grafana frontend, which visualises the stored information for the Train requester. We have further considered the Station’s autonomy by applying a customisable filter for the metadata stream. This means that the admin of the Station still maintains control over the outgoing information. For this, we implemented deny/exclude lists for the metadata stream, which can easily be tailored by the admins according to the present legal circumstances.
¶ Privacy and Security Components
Our infrastructure follows several design principles in order to protect sensitive data records. We assume that the station admin, who is interacting with the station software, is authorised to inspect and release potentially sensitive data, which has been generated in the context of the Train execution (e.g. a query result or model parameters). However, the admin’s authority is limited and is only valid within the institutional borders. Therefore, the admin must not see the results of the preceding stations. The admin further should also be sensitised to the intrinsic activities of the executed Train and the files inside the Train which will be released after the Train has left the institution. To meet these requirements, our station software incorporates a mechanism to inspect the Train contents and visualise added, changed or deleted files (Figure 5 - left). In addition, in case the Train produces query results, the admin is able to audit the file contents themselves. The software detects the changes and only visualises data, which is relevant for the current station by simultaneously hiding information from other stations (Figure 5 - right). This feature enables increased transparency of the contents but masks accordant data as well to make first steps towards data privacy.
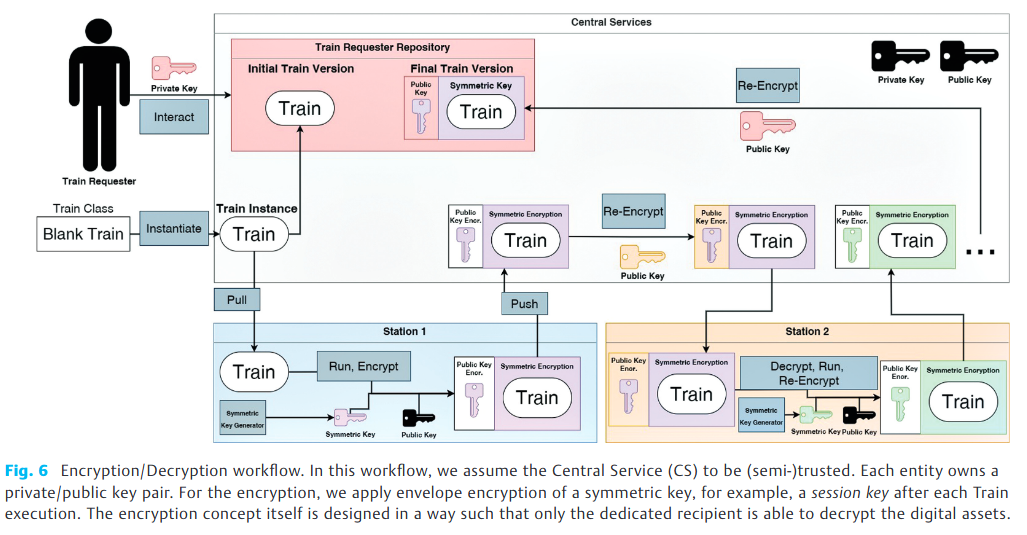
Additionally, our infrastructure follows a private-public key encryption policy, which has been depicted in Figure 6. Firstly, we assume that our CS is considered as (semi-) trusted. We further designed the encryption workflow in a way that no Train is stored in a decrypted format and that only the dedicated recipient can decrypt the digital assets, i.e., the Trains. This approach especially involves the usage of private and public keys for each participating party: Train requester, CS, and Stations. According to our Train lifecycle (Figure 2), the Train requester instantiates a Train instance, which is encrypted by a symmetric key. This symmetric key is generated for each Train request ad hoc. In a second step, the symmetric key is encrypted by the public key of the first station. With this envelope encryption, the Train is securely stored in the Station’s repository until the corresponding Station pulls it. After the Train transmission, the Station reversely decrypts the Train, executes it, and re-encrypt it with the public key of the CS. Then, the CS re-encrypts the Train content with the public key of the next Station. This methodology enables potential error handling, which might be inefficient if the Station encrypts the Train with the public key of the succeeding Station. Due to this reason, we assume the CS as (semi-)trusted such that we remain able to act and redirect a Train in case a Station failure occurs during the Train circulation. In the end, after finishing the Train route, the final Train including the encrypted aggregated results is stored in the requester repository such that only the requester is able to inspect the results.

¶ References
- Chang K, Balachandar N, Lam C, et al. Distributed deep learning networks among institutions for medical imaging. Am. Med. Inform. Assoc. 2018 Aug;25(8):945-54.
- Das A, Upadhyaya I, Meng X, et al. Collaborative filtering as a case-study for model parallelism on bulk synchronous systems. In: ACM Conference on Information and Knowledge Management - CIKM '17. New York, New York, USA: ACM Press; 2017:969–977
- McMahan B, Moore E, Ramage D, et al. Communication-Efficient Learning of Deep Networks from Decentralized Data. In: Artificial Intelligence and Statistics - AISTATS 2016. PMLR; 2017:1273-1282
- Sheller MJ, Reina GA, Edwards B, et al. Multi-Institutional Deep Learning Modeling Without Sharing Patient Data: A Feasibility Study on Brain Tumor Segmentation. Brainlesion. 2019;11383:92-104.
- Su H, Chen H. Experiments on Parallel Training of Deep Neural Network using Model Averaging, July 2015.
- Su Y, Lyu M, King I. Communication-Efficient Distributed Deep Metric Learning with Hybrid Synchronization. In: 27th ACM International Conference on Information and Knowledge Management - CIKM '18, New York, USA: ACM Press; 2018:1463–1472
- Sheller MJ, Edwards B, et al. Federated learning in medicine: facilitating multiple-institutional collaborations without sharing patient data. Scientific Reports. 2020;10:12598
- Beyan O, Choudhury A, van Soest J, et al. Distributed Analytics on Sensitive Medical Data: The Personal Health Train. Data Intelligence 2020;2(1-2):96-107
- Sun C, Ippel L, van Soest J, et al. A Privacy-Preserving Infrastructure for Analyzing Personal Health Data in a Vertically Partitioned Scenario. Stud. Health Technol. Inform. 2019;264:373-377.
- Shi Z, Zhovannik I, Traverso A, et al. Distributed radiomics as a signature validation study using the Personal Health Train infrastructure. Scientific data 2019;6(1):1-8.
- Deist TM, Dankers FJ, Ojha P, et al. Distributed learning on 20 000+ lung cancer patients–The Personal Health Train. Radiother Oncol 2020;144:189-200
- Mou Y, Welten S, et al. Distributed Skin Lesion Analysis Across Decentralised Data Sources. In: 31st Medical Informatics Europe Conference – MIE21, Athens, Greece: 2021: 352–356.
- Wilson RC, Butters OW, Avraam D, et al. DataSHIELD – New Directions and Dimensions. Data Science Journal 2017; 16:21.
- Bonofiglio F, Schumacher M, and Binder H, Recovery of original individual person data (IPD) inferences from empirical IPD summaries only: Applications to distributed computing under disclosure constraints. Statistics in Medicine 2020; 39(8): 1183–1198.
- Pinart M, Jeran S, et al. Dietary Macronutrient Composition in Relation to Circulating HDL and Non-HDL Cholesterol: A Federated Individual-Level Analysis of Cross-Sectional Data from Adolescents and Adults in 8 European Studies. The Journal of Nutrition 2021.
- Zhao C, Zhao S, et al. Secure multi-party computation: Theory, practice and applications. Information Sciences 2019; 476: 357 – 372.
- Doganay MC, Pedersen TB, et al. Distributed privacy preserving k-means clustering with additive secret sharing. In: Proceedings of the 2008 International Workshop on Privacy and Anonymity in Information Society, PAIS’08, New York, USA: ACM, 2008: 3–11.
- Stammler S, Kussel T, et al. MainzellisteSecureEpiLinker(MainSEL): Privacy-Preserving Record Linkage using Secure Multi-Party Computation. Bioinformatics,2020.
- Wüller S, Mayer D, et al. Designing privacy-preserving interval operations based on homomorphic encryption and secret sharing techniques. Journal of Computer Security 2017; 25:59-81.
- Welten S, Neumann L, et al. DAMS: A Distributed Analytics Metadata Schema. Data Intelligence 2021.
- Kermany D, Zhang K, Goldbaum M. Labeled optical coherence tomography (OCT) and Chest X-Ray images for classification. Mendeley data 2018;2(2).
- Kermany DS, Goldbaum M, Cai W, et al. Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell 2018;172(5):1122-31.
- Fang H and Qian Q, Privacy preserving machine learning with homomorphic encryption and federated learning. Future Internet 2021; 13(4):94.
- Li W, Milletarì F, et al. Privacy-Preserving Federated Brain Tumour Segmentation. In: Machine Learning in Medical Imaging, Shenzhen, China; 2019: 133-141.
- Melis L, Song C, et al. Exploiting unintended feature leakage in collaborative learning. In:
Proceedings of 40th IEEE Symposium on Security & Privacy, San Francisco, USA; 2019: 497-512 - Hitaj B, Ateniese G, and Perez-Cruz F, Deep models under the GAN: Information leakage from collaborative deep learning. In: Proceedings of the 24th Conference on Computer and Communications Security, Dallas, USA; 2017:603-618.
- Vatsalan D, Christen P, Rahm E. Incremental clustering techniques for multi-party privacy-preserving record linkage. Data & Knowledge Engineering 2020; 128:101809